GEO, Google, and the governance question few are asking
I have been watching the debate about Generative Engine Optimisation (GEO) with a mixture of professional interest and mild irritation. Most of the discussion is about tactics: how to get your content cited by AI systems instead of ranked by traditional search. That is a legitimate concern. But I think it’s missing the more important question.
The reason GEO exists at all is because Google and other platforms are unilaterally rewriting how content discovery works, and doing it in ways that raise live data protection issues that almost nobody in the GEO conversation is talking about.
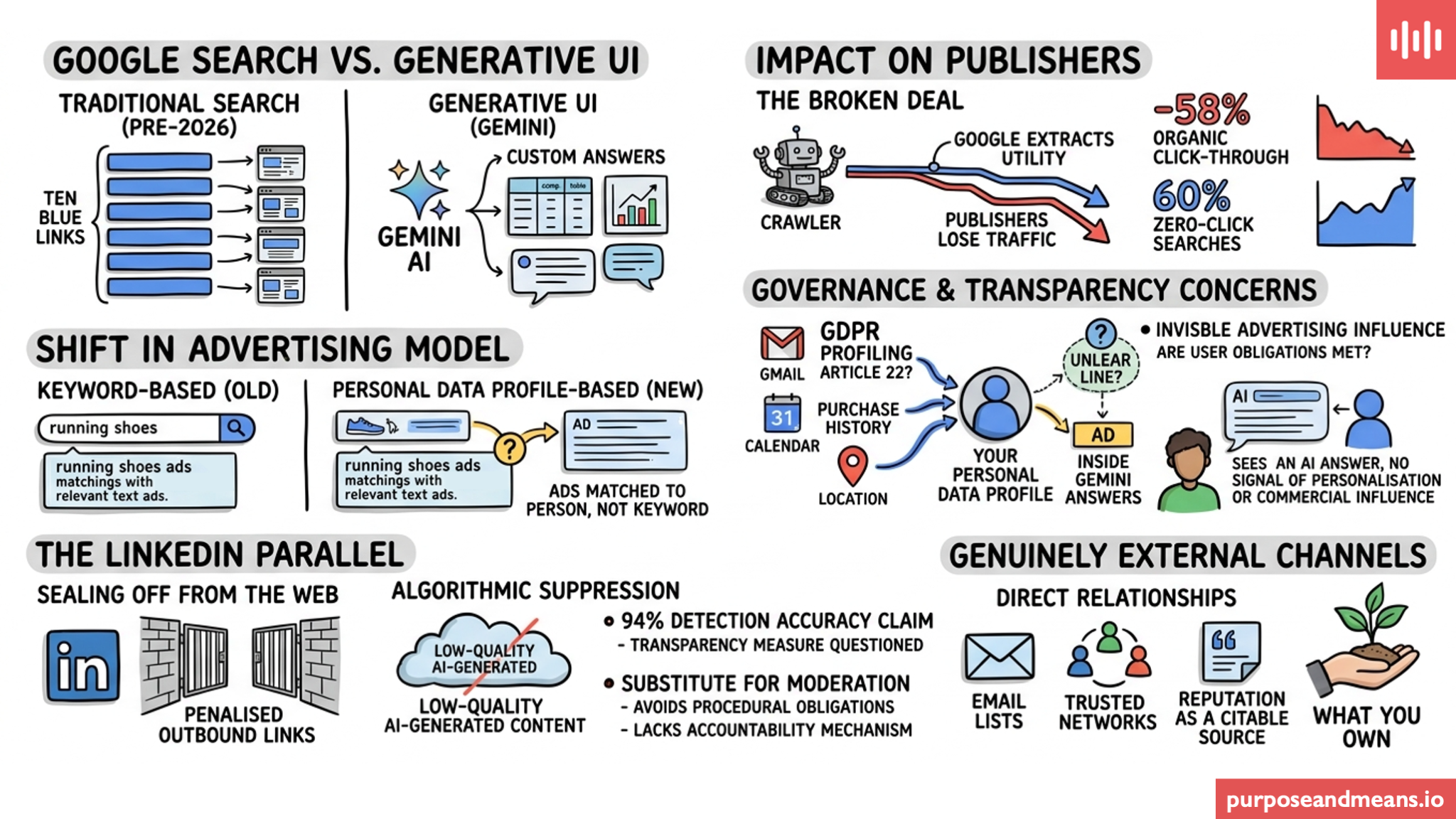
What actually changed at Google I/O 2026 #
Google announced that it is replacing the traditional search results page - those ten blue links that have structured the web since 1998 - with what it is calling “generative UI.” Instead of returning links, Gemini now builds custom answers, widgets, tables and comparisons on the fly, drawing on publisher content without necessarily directing users to the original source.
If you run a website, you’ll see this in your log files. Organic click-through rates for top-ranked results have reportedly dropped by around 58%. Zero-click searches - where users get what they need from the results page itself, without ever visiting a website - now account for roughly 60% of all queries.
That is a structural transformation, not a tweak. The original “deal" that made the open web viable, where publishers let Google crawl their content and Google sent readers back, has been broken. The utility is being extracted, but the traffic is not. There are a couple of excellent articles I recommend that explain this far better than I could - here (Declan Chidlow) and here (Matthias Ott).
Why this matters beyond digital marketing #
If you see this as a problem for website publishers, or a marketing problem, you are only reading half of it. There is a governance dimension here that deserves serious attention.
When search results were keyword-matched links, the advertising model that funded them was also keyword-based. You searched for “running shoes” and you saw ads for running shoes. Your personal data was involved, but the matching logic was at least loosely tied to what you had actively asked.
What Google is building now is different. Inside Gemini-generated answers, ads are not matched to keywords. They are reportedly being matched to personal data profiles e.g., email content, calendar data, purchase history, browsing behaviour, location patterns, inferred health and financial status, and Google holds all this across all of its services. The auction is no longer for a keyword slot. It is for access to a person, inferred from everything Google knows about them, inside a conversational interface where the line between organic answer and paid placement is deliberately unclear.
Under the GDPR, profiling for advertising purposes requires a lawful basis, must meet the transparency requirements under Article 5(1)(a), and raises questions under Article 22 where the profiling contributes to decisions with legal or similarly significant effects on the individual, though whether any specific use crosses that threshold depends on its concrete impact, not the targeting activity alone. When the profiling is embedded inside what looks like an objective AI answer, the transparency problem becomes pretty serious. The person has no visible signal that they are seeing a personalised, commercially influenced response rather than a neutral one.
The EU AI Act adds a further layer. Under Article 50, providers of AI systems that interact directly with users must ensure those users know they are engaging with AI unless that is already obvious from context. That obligation covers the interaction itself. It does not, on its own, cover the commercial targeting embedded within it: the question of whether a response has been shaped by a personal data profile rather than neutral retrieval is a GDPR and ePrivacy question, not an AI Act one. Both obligations apply, but they sit with different responsible parties and address different aspects of the same opacity. Whether either is being meaningfully met inside AI-generated search answers is a question regulators have not yet answered in public (as far as I’m aware).
The LinkedIn parallel #
LinkedIn is doing something structurally similar, but from the opposite direction. Where Google is absorbing the open web into a closed AI answer layer, LinkedIn is sealing itself off from the web entirely. Outbound links are reportedly being penalised in reach algorithms. The platform wants users inside LinkedIn, not following links elsewhere.
LinkedIn also announced that it is suppressing, not removing, content its systems classify as generic AI-generated posts, claiming 94% detection accuracy in early tests. Flagged content remains visible to a poster’s direct connections but is excluded from wider feed recommendations. LinkedIn has indicated the rollout will take several months, so the full effect on content reach is not yet visible, but the mechanism is already active.
The 94% figure is presented as a transparency measure. It is not. A 94% accuracy claim with no published false-positive rate tells you very little about how often legitimate content is being caught in the net. Reach-based suppression is increasingly being used as a substitute for content moderation: it can produce much the same practical effect as removal, but without the procedural obligations that removal would trigger, and without any mechanism for the affected person to understand what happened or challenge it. That is an accountability gap. The GDPR requires that automated decisions affecting people be transparent, challengeable, and subject to human review in certain circumstances. Algorithmic reach suppression sits in a grey zone that I think we all should be watching.

The GEO response and what it misses #
If you run a website, or blog you might be wondering what you can do, and there are a fair few videos on Youtube and ironically LinkedIn posts stating that if AI systems are now the discovery layer, publishers must optimise for AI citation instead of search ranking. Build “canonical answer pages.” Structure content to be easily ingested as authoritative source material. Treat AI citations as a new KPI.
That response is rational given the circumstances because if you want your webpages to be found, you need to work with the systems doing the finding. But it is worth being clear about what this entails. It accepts that the new gatekeepers, i.e. the AI systems controlled by a small number of large platforms, now determine which sources are authoritative, which voices are prioritised, and which perspectives are included in the answers people receive. There is no appeals process for that. There is no transparency layer. There is no equivalent of a search ranking that anyone can independently audit.
The only channels genuinely outside this structure are direct relationships. Things like email lists, trusted professional networks, a reputation as a citable source that organisations and journalists actually use.
What governance professionals should be paying attention to #
If you are responsible for a governance or data protection in your company, a few things deserve active monitoring rather than passive observation.
The first is the lawful basis and transparency of profile-based advertising inside GenAI interfaces. The shift from keyword to personal-data-profile targeting is not incremental. It changes the risk profile of the consent and transparency frameworks your company may have in place, particularly if you rely on Google’s advertising infrastructure for any part of your customer acquisition.
The second is the use of algorithmic suppression as a moderation tool without equivalent due-process protections. If your company communicates through LinkedIn or similar platforms, you are operating in an environment where reach can be administratively reduced with no stated reason, no error rate, and no formal challenge mechanism. That is a dependency worth naming in a risk assessment.
The third is the broader question of what it means to be a citable source in an AI-mediated discovery environment. The companies that will retain visibility are those whose content is structured, authoritative, and genuinely useful and not those who have gamed a ranking algorithm. That is arguably a better filter than the old one. But it still concentrates power over what counts as authoritative in the hands of the systems doing the citation.
The web’s social contract has been rewritten. The replacement has not been negotiated, agreed, or published. It is simply being implemented, at scale, by bigtech companies with the infrastructure to do it unilaterally. That is exactly the kind of structural shift that we, as governance-minded professionals should be watching, not because there is an immediate action item, but because the time to understand a risk is before it lands on your desk with a deadline attached.
Frequently Asked Questions #
What is Generative Engine Optimisation (GEO)? GEO is the practice of structuring content so that it is surfaced, cited, or paraphrased by AI-powered search and answer systems - such as Google’s Gemini-driven search interface - rather than simply ranked in traditional link-based results. As AI systems increasingly generate direct answers rather than returning links, being cited as a source becomes more valuable than appearing in a ranked list. GEO involves writing clear, structured, authoritative content that AI systems can identify as a reliable answer to a specific question.
Does GDPR apply to AI-generated advertising inside search results? Yes, in principle. Where advertising inside AI-generated search answers is targeted using personal data profiles - including inferred data from email, browsing history, location, or purchase behaviour - the relevant GDPR obligations around lawful basis, transparency, and profiling apply to the controller responsible for that targeting. Whether existing consent mechanisms and transparency notices adequately cover this specific use is a live question, particularly where the nature of the personalisation is not visible to the data subject.
What is the data protection concern with algorithmic reach suppression on platforms like LinkedIn? Reach suppression - reducing the distribution of content without removing it - produces many of the same effects as content removal but operates below the threshold that typically triggers transparency or appeal rights. Where suppression is driven by automated classification, questions arise about transparency (does the affected person know it happened?), accuracy (what is the false-positive rate?), and redress (is there a meaningful way to challenge the decision?). Under the GDPR, fully automated decisions that produce significant effects on individuals must meet specific conditions under Article 22. Whether algorithmic reach suppression crosses that threshold in a given case depends on the specific circumstances, but the lack of published accuracy data and the absence of appeal mechanisms are legitimate governance concerns.