Beyond legal #9: Get to know your SDLC
If you are spending most of your time reviewing contracts and updating RoPAs instead of influencing how your software and products get built you need to get your hands dirty with your SDLC.
DATA PROTECTION MATURITYDATA PROTECTION LEADERSHIPGOVERNANCE
Tim Clements
9/23/20258 min read

In the last post, I suggested it would be worth your while recruiting a data protection engineer. Let’s say, you did that and we fast forward to the engineer’s first day. That person is now sitting at their desk, laptop open, ready to go but have you cleared the way so they can add value from day 1?
Many data protection teams only get involved in projects after the coding is done. The privacy notices get reviewed, the RoPA gets updated, but meanwhile one of the software development team deploys a feature that stores indefinite user session data. And by the time anyone with data protection competences gets involved, it's the same old story about retrofitting controls into a system that was never designed for them, the costs involved, the impact to the promised golive date, and all the expectations that have been given to leadership.
So someone decides to ignore your concerns, and “accept the risk” (which never gets documented anyway).
You hired the data protection engineer to influence how software gets built, so if you’re not careful, you may have just hired an expensive compliance reviewer who'll spend their time writing post-mortem reports about data protection violations that could have been prevented.
This is why integrating data protection into your Software Development Life Cycle (SDLC) isn't just a nice to have, it's the foundational competence that determines whether your data protection engineer becomes a valued enabler or an expensive (and soon to be) frustrated pen pusher.
What SDLC integration actually means
SDLC integration gives you the opportunity embed data protection requirements, security controls, and compliance evidence into every stage of software development. It starts at requirements elicitation through to production monitoring. And the good thing for data protection leaders is, it's a repeatable approach that ensures data protection becomes an engineering deliverable and not a legal afterthought, or bolt-on.
I believe there are too many companies that still treat data protection as something that happens "around" software development, which often manifests in wonky implementations. Common examples include long-winded privacy notices that are so far from being clear and concise, RoPAs are too high level, rarely updated and siloed from the rest of the company, and clunky cookie banners that create user friction and fatigue. And then the actual data processing, the retention and deletion mechanisms, the access controls, the dataflow controls - these are engineering decisions that should get baked in to code. If your data protection competences aren't influencing these decisions, you're not doing data protection, you're doing “compliance theatre.” It really is the difference between bolt-on compliance and built-in protection.
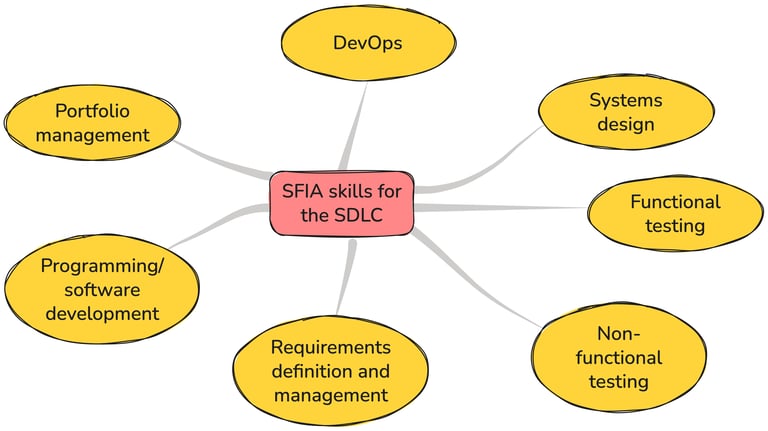
The SFIA competencies you need
As with previous posts, I want to anchor this in the SFIA framework because these are measurable and definable skills that you can recruit for, or develop from within your company:
DevOps: Your data protection engineer needs to understand continuous integration (CI) and continuous delivery (CD) pipelines, automated testing, and infrastructure as code. They can't influence what they can't access. In SFIA, a specific view has been developed to support DevOps.
Systems Design (DESN): Translating functional and non-functional including DPIA outputs and legal requirements, into architectural patterns and technical specifications that developers can implement.
Functional testing (TEST) and Non-functional testing (NFTS): Data protection controls need to be tested like any other functionality. For example, can users export their data, does data erasure actually work, are consent preferences persisted correctly? Also testing to evaluate performance, security, scalability and other non-functional qualities against requirements.
Requirements definition and management (REQM): Converting abstract legal obligations into specific, testable user stories that can be prioritised into sprint backlogs.
Programming/software development (PROG): Understanding enough about code to review pull requests, design secure APIs, and spot data protection concerns.
Portfolio management (POMG): Understanding how data protection requirements flow through your company’s project portfolio governance and approval processes.
As a data protection leaders, if you don’t have access to people with these competences, they'll remain dependent on others to translate their requirements, creating friction and misunderstanding at every stage.
Governance integration
Before we look deeper into sprint-level integration, I just want to highlight an important upstream competence that many data protection leaders overlook - project portfolio and project governance integration. Data protection considerations must be addressed at the project initiation stage. You should not wait to think about this during development sprints.
Every project initiation document (PID), or project charter, should include mandatory data protection requirements sections. These are gates that should be part of the criteria whether a project gets approved, for example, does the project budget include addressing these requirements, as well as triggering required data protection resource involvement. The considerations could include:
What categories of personal data will be processed?
What are the volumes of data?
What's the nature, and risk of the intended processing?
Are there cross-border transfer implications?
What are the retention and deletion requirements?
Is a DPIA required?
What data protection engineering patterns will be required?
I also suggest your company’s project portfolio management processes include a data protection team member on approval boards. This person should have voting authority and the mandate to prevent projects from proceeding without appropriate data protection considerations. I've seen too many situations where data protection teams are consulted on projects that are already 80% designed, resulting in last minute bolt-ons being applied that are often ineffective and expense.
Integration sprints
To get a bit more practical, here's an example of a 5 week implementation plan with data protection considerations for each stage:
Week 1: Preparation
Days 1-2: Governance integration
Review your project initiation template (PID) and add mandatory data protection fields
Identify which approval boards need data protection representation
Draft an easy to understand one-pager aimed at project managers and their teams
Days 3-4: Sprint planning
Add these data protection related questions to your sprint planning template:
What personal data does this feature collect, process, or store?
What is the legal basis for this processing, and if consent, how will preferences be managed?
How long do we need to retain this data, and how will deletion be implemented?
Are there any automated decision-making or profiling aspects?
What third parties will have access to this data?
Does this create cross-border data flows?
Days 5-7: Team education
Run a half-day workshop with your development teams covering contextual data protection by design and by default patterns
Introduce threat modeling using a framework like LINDDUN
Provide developers with a “data protection anti-patterns" guide covering common mistakes like logging identifiers, indefinite data retention, reusing data indiscriminately, or covering up personal data breaches
Week 2: Automated testing implementation
Days 8-10: Basic data protection test suite
Start with one automated test that validates core functionality, such as:
Can the system export a user's complete data profile via API?
Does user deletion cascade properly through all related data?
Does the user’s data persist in cache, backups, or third-party integrations after deletion?
Are all processing activities traceable and matched against RoPA entries?
Days 11-12: Security scanning integration
Implement automated secret scanning in your CI/CD pipeline to catch API keys, database credentials, and hardcoded personal data
Add Static Application Security Testing (SAST) rules specifically for data protection violations including personal data in logs or unencrypted sensitive data storage
Days 13-14: Data classification automation
Implement automated data discovery tools that can identify personal data in databases, APIs, and log files
Create alerts for when new personal data categories are detected in systems
Periodic manual validation complements automated tools, as many DLP/discovery tools still generate false positives/negatives.
Week 3: Developer workflow integration
Days 15-17: Pull request data protection checklist
Add these mandatory questions to your PR template:
Does this code collect, process, or store personal data? If yes, document the data categories, purpose of processing and legal basis
Have you implemented appropriate retention periods and deletion mechanisms?
Does this code log any personal data? If yes, justify why it's necessary and ensure proper redaction
Are there any hardcoded personal data, API keys, or credentials? (Should be caught by automated scanning)
Is data minimisation respected and could this feature work with less data?
Does this create any automated decision-making that affects users?
Days 18-19: Privacy-aware code libraries
Create reusable components for common privacy and data protection patterns:
Consent management and preference persistence
Data export APIs with standardised formats
Secure logging that automatically redacts personal data
Retention policy enforcement with automated deletion jobs
Pseudonymisation utilities for analytics datasets
Days 20-21: Architecture review process
Establish data protection review checkpoints in your architecture decision records
Create templates that require architects to address data flows, storage locations, encryption requirements, and access controls
Week 4: Production monitoring and continuous improvement
Days 22-24: Monitoring implementation
Set up monitoring dashboards for unusual data access patterns
Implement automated alerts for potential data protection violations such as bulk data exports, failed deletion jobs, or processing inconsistencies
Create automated reports for data subject request SLAs and completion rates
Make use of User Behaviour Analytics (UBA) to identify anomalous access to personal data
Expand monitoring to cover emerging threats, such as shadow IT or unsanctioned data flows
Days 25-26: Incident response integration
Update incident response procedures to include data protection-specific actions
Establish automated personal breach detection rules in your SIEM system
Create runbooks for common data protection incidents like accidental personal data exposure
Integrating with change management triggers, so any significant new processing automatically initiates a review
Days 27-28: Evidence generation
Implement automated compliance reporting that provides evidence of control effectiveness
Set up audit trails for all data access, modification, and deletion activities
Create automated DPIA monitoring that alerts when processing activities change significantly
Week 5: Retrospective
Days 29-30: Evaluation and planning
Run a comprehensive retrospective focused specifically on data protection integration:
What worked well?
Which gates prevented actual data protection violations?
What automated tests caught issues before deployment?
How did developers respond to data protection requirements in their workflow?
What created friction?
Where did data protection requirements slow down development unnecessarily?
Which data protection and privacy patterns were difficult to implement or understand?
What approval processes created bottlenecks without adding value?
What needs refinement?
Which tests produced false positives or missed real issues?
How can we make privacy and data protection patterns easier for developers to adopt?
What additional automation would reduce manual data protection reviews?
Key metrics to track:
Number of data protection-related pull request rejections
Mean time to fulfil data subject requests
Data protection incidents caused by code defects
Developer compliance with data protection checklists
Three common pitfalls to avoid
Pitfall 1: Data protection theatrics
Adding data protection checkboxes to workflows without enforcing them. If developers can ship code that fails data protection tests, then all you are doing is creating theatre.
Pitfall 2: Over-engineering
Trying to solve every data protection problem in the first sprint. Focus on your high risk data flows first, perfect the patterns, then expand systematically.
Pitfall 3: Governance bypass
Allowing "urgent" projects (or leadership "pet" projects) to skip data protection reviews. Every exception becomes a precedent that undermines your entire integration effort.
Conclusion
Compared with earlier posts in this series, this post covers a more “in the engine room” set of skills, and data protection leaders need to at least to get an understanding of what is happening behind the scenes. It also represents a fundamental shift from reactive compliance to proactive engineering. Instead of your data protection team being the people who explain why you can't do something, they become the people who help you do it correctly from the start.
It transforms conversations from "Legal says no!" to "Here's a privacy-preserving analytics pattern that gives you the insights you need while meeting our retention requirements." That's the difference between being seen as a necessary evil and being valued as a strategic enabler.
Your data protection engineer shouldn't be reviewing privacy notices and updating RoPAs. They should be reviewing system architectures, designing secure APIs, ensuring that controls are tested in every deployment, and most importantly, sitting on approval boards where technical architecture decisions get made.
As a data protection leader, ask yourself this question. Can you influence your company’s next product or software release from project initiation through to production monitoring? If not, you need to onboard the competences mentioned above pretty quickly.
Purpose and Means is a niche data protection and GRC consultancy based in Copenhagen but operating globally. We work with global corporations providing services with flexibility and a slightly different approach to the larger consultancies. We have the agility to adjust and change as your plans change. Take a look at some of our client cases to get sense of what we do.
We are experienced in working with data protection leaders and their teams in addressing troubled projects, programmes and functions. Feel free to book a call if you wish to hear more about how we can help you improve your work.

Purpose and Means
Purpose and Means believes the business world is better when companies establish trust through impeccable governance.
BaseD in Copenhagen, OPerating Globally
tc@purposeandmeans.io
© 2026. All rights reserved.